The Best Fluffy Pancakes recipe you will fall in love with. Full of tips and tricks to help you make the best pancakes.
Comment illustrer un dialogue FLE en vidéo grâce à l’IA

Vous n’en pouvez plus des dialogues des méthodes d’enseignement audio-orales, où les personnages n’ont aucune personnalité et ne transmettent aucune émotion ? Dans un article précédent, nous avons vu comment transformer une célébrité en enseignant de FLE grâce à l’IA. Maintenant, et si nous pouvions faire interagir cette célébrité avec un autre interlocuteur, pour créer un dialogue (semi) authentique ?
Nous allons vous montrer comment le faire en prenant l’exemple de Trump entrant (fictivement) dans un magasin pour chercher des lunettes de soleil, avec un dialogue de niveau A1, ce qui permet de travailler le vocabulaire lié au magasins, vêtements et couleurs.
Étape 1 : Choix du dialogue
Le dialogue entre Trump et une responsable de magasin est créé par nos soins et ressemblera à ceci.
| – Bonjour madame. – Bonjour monsieur. – Je voudrais acheter des lunettes, des belles lunettes de soleil. – Des lunettes comme ça ? Comme Manu ? – Oui c’est ça, comme Manu. Je voudrais être cool comme Manu. S’il vous plaît. – OK, essayez celles-là. – Non, pas en bleu. Je les voudrais en rouge. – Ok, les voilà en rouge. – Oui voilà. Non, ça c’est trop petit. Un peu plus grand. – Vous êtes difficile ! – Super, merci ! – Au revoir, bonne journée. |
Ensuite, pour faire un dialogue, il nous faut animer les deux personnages séparément, l’un après l’autre.
Etape 2 : Animer Trump (célébrité)
Notre texte d’animation pour Trump sera celui-ci, extrait de notre texte précédent :
| Bonjour madame. Je voudrais acheter des lunettes, des belles lunettes de soleil. Oui c’est ça, comme Manu. Je voudrais être cool comme Manu. S’il vous plaît. Non, pas en bleu. Je les voudrais en rouge. Oui voilà. Non, ça c’est trop petit. Un peu plus grand. Super. Merci. Merci beaucoup. Au revoir, bonne journée. |
Sur la plateforme VoidMagic : https://voidmagic.ai/ai-celebrity-voice-generator, la voix de Trump est déjà disponible (comme de nombreuses autres célébrités). Je n’ai donc pas besoin de la cloner comme je l’avais fait avec Macron. Il suffit de choisir la voix puis d’insérer le texte voulu.
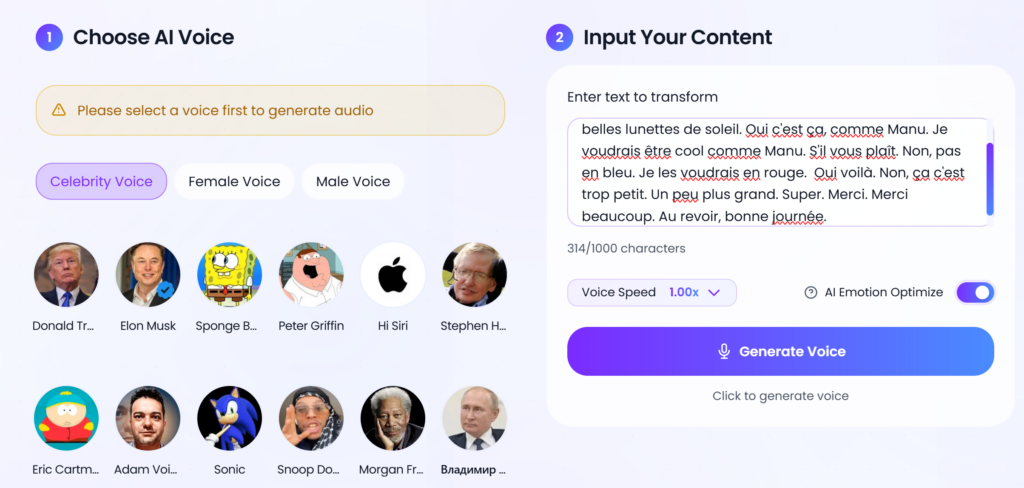
Ensuite, j’ai utilisé lipsync.video pour le Lip Sync photo ensuite, avec l’algorithme Talking Photo 4.0. Voici le résultat.
Je n’aime pas trop la pose de Trump, alors j’ai voulu essayer avec une autre photo. Je voulais voir Trump dans un magasin de lunettes. Comme il n’existe pas de photo mettant Trump dans un magasin de lunettes, j’ai donc dû créer cette « photo ». A cet effet, j’ai utilisé l’IA Imagine.art.
Voici mon prompt et le modèle utilisé (Nano Banana Pro, gratuit). J’ai écrit en anglais, car parfois l’IA comprend mieux quand on lui parle en anglais, la majorité des utilisateurs étant anglophones.

Ensuite, j’ai utilisé Mango Animate pour le lipsync photo gratuit par l’IA, avec le modèle Mango AI 1.0.
Le résultat est… nul… alors n’utilisez pas Mango Animate. Je vous laisse voir par vous-même :
Seules les lèvres bougent, le visage n’a pas d’expression.
J’ai essayé ensuite la plateforme Magic Hour, avec un bien meilleur résultat. On ne peut faire que 10s de génération vidéo à la fois, avec 3 vidéos maximum dans la version gratuite. Comme mon audio faisait 19s, j’ai coupé l’audio avec l’outil gratuit : https://mp3cut.net/
Voici le résultat final côté Trump pour la première moitié du dialogue :
Comme le résultat me satisfaisait, j’ai fait l’autre moitié du dialogue, puis j’ai continué avec l’autre interlocutrice de la vidéo.
Etape 3 : Animer l’interlocutrice virtuelle
L’interlocutrice étant cette fois une personne fictive et non une célébrité, j’ai refait le même travail, cette fois avec une voix de femme artificielle et une image de femme dans un magasin de lunettes trouvée sur Google, et le texte suivant extrait de notre dialogue de départ :
| Bonjour monsieur. Des lunettes comme ça ? Comme Manu ? OK, essayez celles-là. Ok, les voilà en rouge. Vous êtes difficile ! Bonne journée ! |
Cette fois, comme la jeune femme est un personnage fictif (et non représentant une personne célèbre), j’ai choisi une voix artificielle déjà existante, sur Voidmagic. J’aurais aussi pu en prendre une via ElevenLabs par exemple.
J’ai utilisé l’algorithme Taking Photo 1.0 de lipsync.video comme il ne me restait pas assez de crédits pour prendre la version avancée.
Les résultats sont ci-dessous :
L’algorithme est de bien moins bonne qualité. Pour avoir un meilleur rendu au niveau des lèvres, je me suis alors tournée vers un autre outil,
J’ai d’abord essayé sync.so . Pour utiliser cette plateforme en lip sync, il faut absolument mettre une vidéo, pas une photo. J’ai alors utilisé la vidéo générée par l’IA d’avant, comme je n’avais pas de vraie vidéo de la fille.
En faisant une capture écran, j’ai pu enregistrer la vidéo générée en preview sans utiliser mes crédits de téléchargement (3 téléchargements gratuits maximum).
Je ne vois personnellement pas trop de différence avec la génération du site d’avant.
Puis j’ai essayé Heygen, en créant un avatar virtuel à partir de la même photo trouvée précédemment. J’ai mis une seule photo. Puis j’ai simplement donné le texte et la plateforme a généré une voix avec.
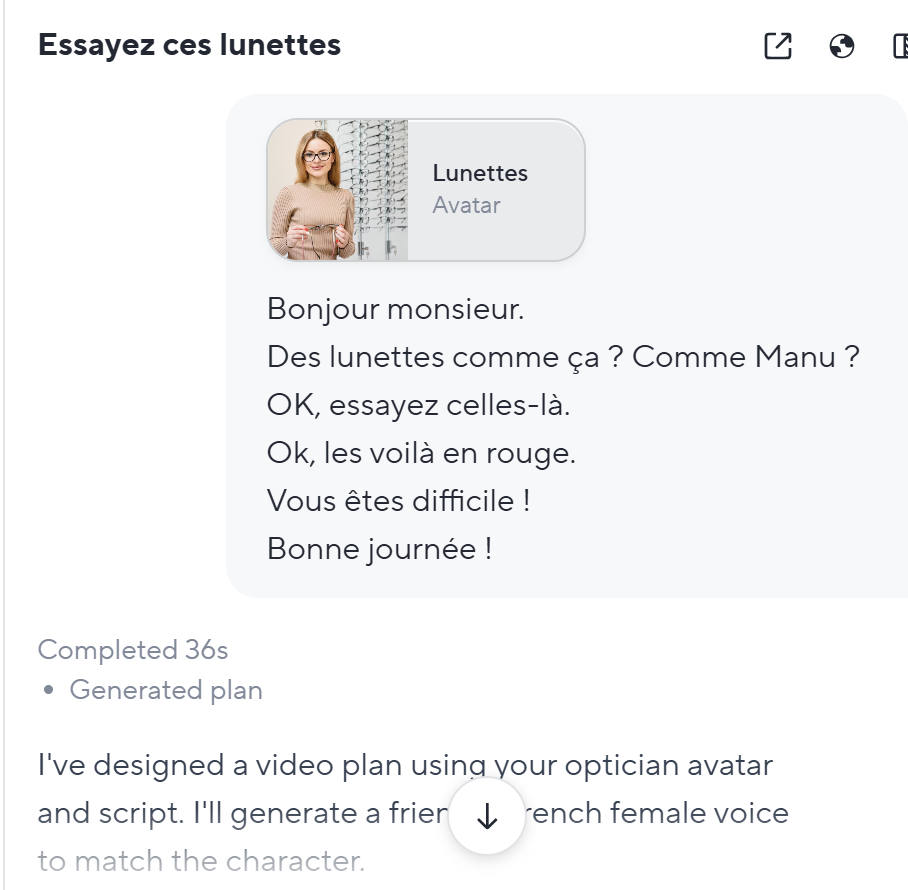
Le résultat est bien meilleur en termes d’émotions. Par contre, ça a coupé un peu du texte original – l’outil prompting de Heygen n’est pas très rigoureux.
Leçon apprise : n’utilisez le lipsync que pour des célébrités. Pour le reste, si vous avez un peu de flexibilité sur le texte, utilisez Heygen.
Note : Heygen m’avait généré la vidéo avec des sous-titres, alors j’ai dû lui demander par prompt de me donner la vidéo sans sous-titres cette fois. Comme il ne semble pas y avoir d’option pour simplement avoir la vidéo sans sous-titres, il est obligé de la régénérer si on ne lui a pas déjà donné l’instruction de ne pas mettre de sous-titres.
Etape 4 : Rassembler les deux vidéos
J’ai monté le tout sur Capcut, en coupant entre les dialogues et en rajoutant quelques effets, et le résultat donne ça en HD :
Bilan des étapes à suivre
- Choisir/préparer le dialogue
- Animer l’interlocuteur célébrité avec VoidMagic pour la voix, MagicHour pour la vidéo en coupant l’audio si nécessaire avec https://mp3cut.net/
- Animer l’interlocuteur virtuel avec Heygen
- Monter les vidéos ensemble
Conclusion
Une fois qu’on connaît les bons outils, la génération en elle-même est très rapide. Ce qui prend du temps, c’est de tester chaque outil disponible sur Internet parmi la myriade de disponibles. J’espère donc vous faire gagner du temps en vous partageant ici précisément les outils gratuits qui ont marché pour moi.
Bonus : génération de vidéo pure
J’ai voulu ajouter des bouts de clip où on voit une main pousser des lunettes de soleil à Trump.
L’outil d’Adobe Firefly https://firefly.adobe.com/generate/video est surprenant en qualité, il y a 3 générations gratuites de vidéo.
J’ai utilisé le prompt suivant très simple :
| crée une vidéo qui montre des mains féminines poussant des lunettes de soleil bleues sur une table marron foncé. |
Et j’ai refait la même chose avec la couleur rouge, voici le résultat :
Sinon, j’ai aussi trouvé l’outil Upsampler https://upsampler.com/free-video-generator-no-signup , utilisant l’IA Wan gratuitement, 1 vidéo par jour, avec le modèle Wan 2.2 5B. La qualité est moins bonne mais largement suffisante pour notre vidéo désirée.
Annexe : Minimax
Dans mon article précédent, j’avais utilisé Minimax pour cloner la voix de Macron. L’outil permettait une plus grande personnalisation des pauses, et maintenant même des émotions.
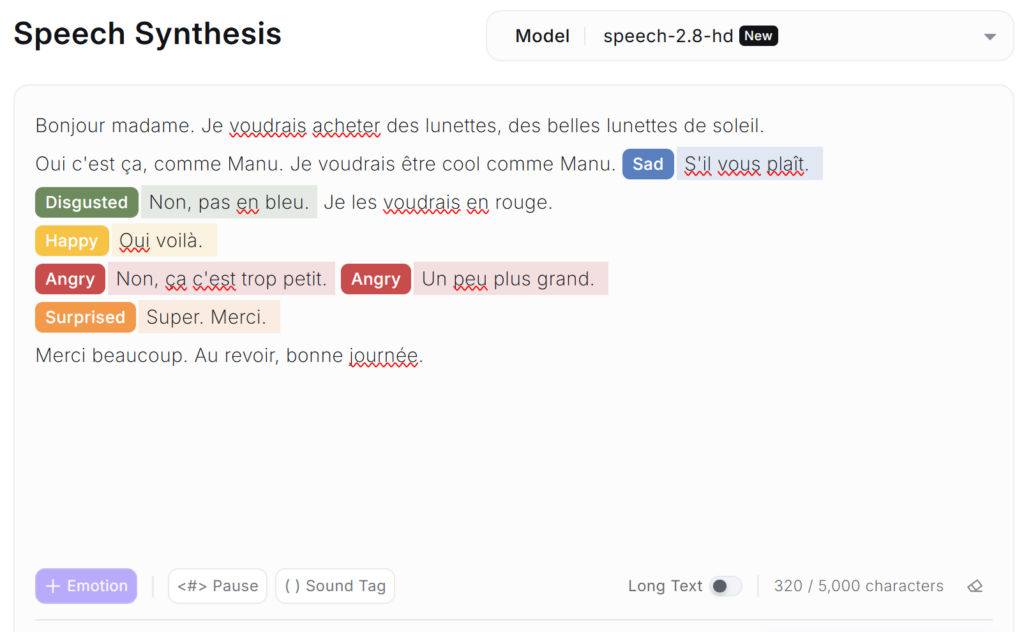
Malheureusement, les serveurs étaient en panne au moment où je faisais le clonage de voix. C’est pour ça que je me suis tournée vers Magic Void pour utiliser une voix de célébrité existante.
Depuis, les serveurs remarchent ! J’ai utilisé DeepAI pour créer une autre photo de Trump (de meilleure qualité que Imagineart), et à nouveau Magic Hour pour le lip syncing. Le résultat est le suivant :